Showing posts with label High Availability. Show all posts
Showing posts with label High Availability. Show all posts
Monday, April 8, 2024
Wednesday, March 30, 2022
We love MongoDB for extraordinary features as per business perspective
Lets come to our Blog Discussion , Only in PaaS Environments we have features like DNS endpoints for database easily connect with primary or secondary at any single point of failure
Mongo Atlas Providing all the features but small scale customers still using MongoDB with Virtual Machines or EC2 Instances . To handle point of failures in primary we can use DNS Seed List Connection Format in mongoDB . We will discuss in detail how to we configure this in AWS Cloud
What is seed list ?
Seed list can be list of hosts and ports in DNS Entries . Using DNS we can configure available mongoDB servers in under one hood . When client connects to an common DNS , its also knows replica set members available in seed list . Single SRV identifies all the nodes associated with the cluster . Like Below ,
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false" Percona Server for MongoDB shell version v4.4.13-13 connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false

Environment Setup :
For Testing Purpose , We have launched 3 Private Subnet Servers and 1 Public Subnet Server to use like Bastion . Create One Private Hosted Zone for DNS and Installed Percona Server for MongoDB 4.4.13 then configured Replication in it
AWS EC2 Servers ,

Route 53 Hosted Zone ,

Creating A Records :
We have launched private subnet instances , so we required to create A Records for private IP's . If Public IPv4 DNS available we can create CNAME Records
A Records Created for db1 server ,
Inside the datamongo.com hosted Zone , Just Click Create Record

Same like we need to create A Records for other two nodes

Verify the A Records ,
root@ip-172-31-95-215:~# dig db1.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db1.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 13639 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db1.datamongo.com. IN A ;; ANSWER SECTION: db1.datamongo.com. 10 IN A 172.31.85.180 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 11:58:09 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db2.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db2.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9496 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db2.datamongo.com. IN A ;; ANSWER SECTION: db2.datamongo.com. 300 IN A 172.31.83.127 ;; Query time: 3 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:28 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db3.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db3.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46401 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db3.datamongo.com. IN A ;; ANSWER SECTION: db3.datamongo.com. 300 IN A 172.31.86.8 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:33 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~#
Creating SRV and TXT Records :
As like Atlas , Once we have the A Records for MongoDB Nodes , we can able to create SRV Records
Again Inside the datamongo.com hosted Zone , Just Click Create Record

Once its created , again click create record and create TXT records


Reading SRV and TXT Records :
We can use nslookup and verify the configured DNS Seeding ,
root@ip-172-31-95-215:~# nslookup > set type=SRV > _mongodb._tcp.db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: _mongodb._tcp.db.datamongo.com service = 0 0 27717 db2.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db3.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db1.datamongo.com. Authoritative answers can be found from: > set type=TXT > db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: db.datamongo.com text = "authSource=admin&replicaSet=db-replication" Authoritative answers can be found from:
Verify Connectivity :
Its all done , We can verify the connectivity with DNS Seed List Connection format ,
By Default , it will connect with ssl true , but we have configured mongodb without SSL . If you required to configure with SSL please refer our blog and configure DNS Seeding with help of this blog
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"
Percona Server for MongoDB shell version v4.4.13-13
connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false
Implicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }
Percona Server for MongoDB server version: v4.4.13-13
---
The server generated these startup warnings when booting:
2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem
---
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;
172.31.83.127:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;
PRIMARY
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;
172.31.85.180:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;
SECONDARYCurrently 172.31.83.127 is the primary server and 172.31.85.180 is secondary , to test connection we have stopped the primary server (172.31.83.127) in AWS console
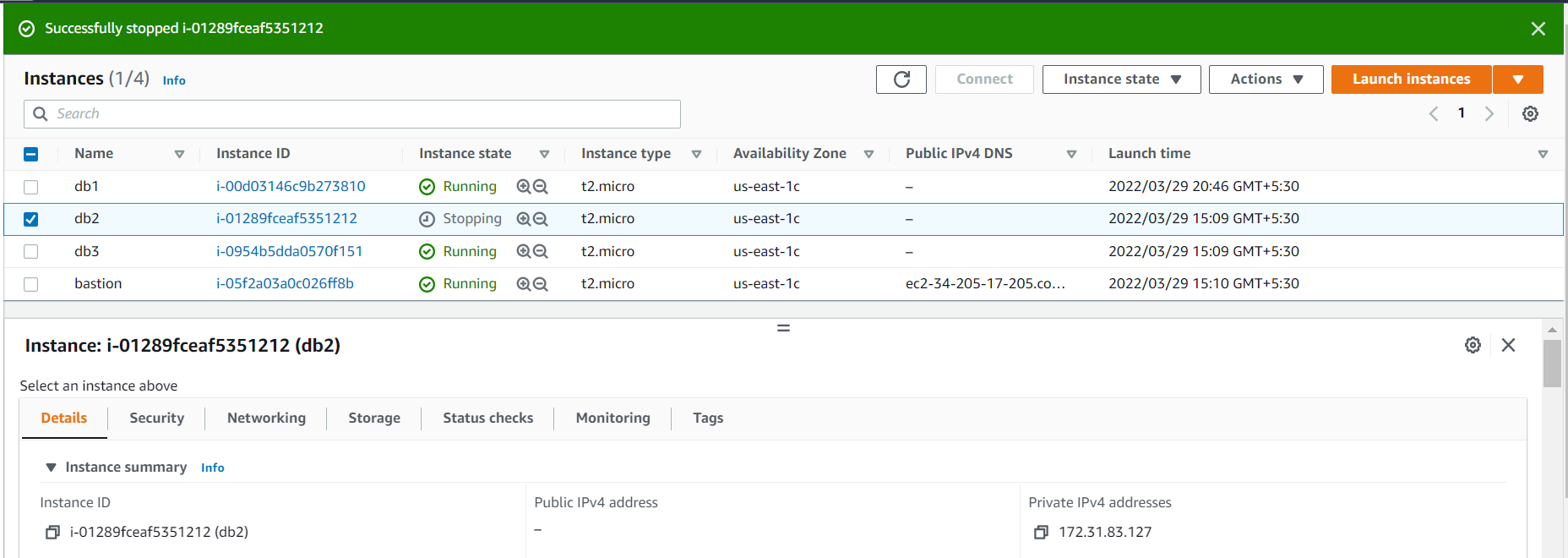
after stopping primary server (172.31.83.127) , mongodb failover happened to to 172.31.85.180 . Its verified without disconnecting the mongo shell
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"Percona Server for MongoDB shell version v4.4.13-13connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=falseImplicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }Percona Server for MongoDB server version: v4.4.13-13---The server generated these startup warnings when booting:2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem---db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.83.127:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;SECONDARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARY
Its working as expected and we have no worries if anything happens on mongoDB primary node in Cloud IaaS as Well !!!
Please contact us if any queries and concerns , we are always happy to help !!!
Wednesday, February 16, 2022
Microsoft gives HA features like a charm . Lower to higher deployment costs its giving many features as per business requirements . Replication , Mirroring , Log shipping and Always On many features available to build HA Setup in On Premises .
Like wise , we can setup all the above features in Cloud as well . In that we can see Always on availability group cluster in this blog

What is Always On Availability Group?
- An availability group supports a replicated environment for a discrete set of user databases, known as availability databases.
- You can create an availability group for high availability (HA) or for read-scale. An HA availability group is a group of databases that fail over together.
Environment Setup for Always on Availability Group ,
Launched one Active Directory and two SQL Nodes with below range . Detailed setup for environment steps are below ,

Step 1 : Create ag-sql-vpc with 10.0.0.0/16 IPv4 CIDR range


Step 3 : Launched the windows instances with two secondary ip's for Failover Cluster and Always on Listener
In this POC Setup , Launched windows instance and installed SQL Server Developer edition . Also we can launch Windows with SQL Server 2016 based on your requirements



Step 4 : Change the computer properties and rename the instance names accordingly
Step 5 : Completed the AD Server configuration and its named as ag-sql-AD , After that change DNS server address in network properties in ag-sql-node1 and ag-sql-node2 ( 10.0.4.33 is static IP of AD Server )

Step 6 : Once modified the DNS configuration reboot the server and login with AD administrator account
Step 7 : Once logged in with AD login , Install the failover clustering and below dependent features in ag-sql-node1 and ag-sql-node2

Configuring Shared Drive for Backup and Restore
Step 8 : Between the ag-sql-node1 and ag-sql-node2 needs to take backup and log backups for Always on background process
Step 9 : Create folder in ag-sql-node2 and share with everyone in AD account
Step 10 : Take one time backup of DW_Mart and DataLake in that shared folder . Created Shared drive will be used while always on group creation
Failover Cluster Configuration
Step 11 : Open the Failover Cluster Manager console and Create the cluster . Browse and add the both servers


Once we added both secondary IP's one of the IP will be come to online

If we have not added secondary IP , it will show as an error like below

Configuring SQL Server Services
Step 14 : Once all the steps are completed on Failover cluster manager , modify the SQL Service Account to AD service account
Step 15 : Next right click the SQL Server Service in configuration manager and enable the Always on High Availability on ag-sql-node1 and ag-sql-node2 SQL instances

Create and Configuring the Availability Group
Step 16 : Right click the always on group wizard and create the availability group as agsqldb

Step 17 : Based on the requirements add the number of replicas ,

Step 18 : Below are the endpoints and make sure allowed below ports between the cluster nodes

Step 19 : Then create availability group listener with remaining secondary IP ( 10.0.1.12 and 10.0.3.12 )

Step 20 : Once everything is completed click Next to create availability group


Ready to sync the Data from Primary to Secondary
After all availability group is healthy and primary and secondary nodes are synchronized

Thanks for Reading !!! Any corrections or any doubt please contact me directly !!!
Wednesday, February 19, 2020
It is easy to migrate the MySQL databases from one cloud provider to another cloud provider , but without downtime is little difficult to migrate the 1 TB of data . Using GTID based replication is easy to achieve in few hours of effort
Before go into detail , we will go through explanations of each things,
What is Cloud MySQL ?
Google Cloud Managed service for MySQL Database servers . It is supporting MySQL 5.6 and 5.7 with first and second generation instances . First and Second generation differs with allocating RAM and Storage
What is Percona xtradb cluster ?
Synchronous multi-master replication using percona MySQL server and percona xtrabackup using galera Library . As recommended it should contains odd number of nodes and same data spanned with all nodes
What is multi-source replication ?
MySQL multi-source replication enables a replication slave to receive transactions from multiple immediate masters in parallel
In this scenario , we have to migrate more than 3 GCP Cloud MySQL Managed instances into
Percona Galera Cluster . Before proceed to migrate the data , it is requires to compare MySQL 5.7 and Percona MySQL 5.7
https://www.percona.com/doc/percona-server/5.7/feature_comparison.html
So that we can avoid impact after migrating the data into new server
Instructions follow to setup multi source replication ,
- In GCP MySQL Instance , take a user database backup from each instances separately through mysqldump or using export in GCP GUI Console and move to backup files to destination server using gsutil or scp utility
mysqldump --user=root --password --host=gcpinstance1 sourcedb1 > mysqldump1.sql
mysqldump --user=root --password --host=gcpinstance2 sourcedb2 > mysqldump2.sql
- Before goes to next steps , we have to ready with three node percona XtraDB cluster environment before proceeds with next steps
- In Percona XtraDB Cluster end , need to modify below server variables in my.cnf file for GTID based replication and restart mysql service
[mysqld]
server-id=[SERVER_ID]
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
replicate-ignore-db=mysql
binlog-format=ROW
log_bin=mysql-bin
expire_logs_days=1
read_only=ON
Same Changes needs to edit for additional node of percona cluster
- Restore multiple source cloud mysql backup into one percona cluster instance
mysql --user=root --password --host=perconainstanceslave < mysqldump1.sql
mysql --user=root --password --host=perconainstanceslave < mysqldump2.sql
- Once restore is completed , we need to add multiple source of GCP Cloud MySQL instances into single percona cluster instance using below command
CHANGE MASTER TO MASTER_HOST="gcpinstance1", MASTER_USER="slaveuser1",MASTER_PASSWORD="slaveuser1", MASTER_PORT=3306, MASTER_AUTO_POSITION = 1;
CHANGE MASTER TO MASTER_HOST="gcpinstance2", MASTER_USER="slaveuser2",MASTER_PASSWORD="slaveuser2", MASTER_PORT=3306, MASTER_AUTO_POSITION = 1;
One we execute this , we will get below error due to applied transactions exists already in slave server or we will get duplicate transactions issues commonly
Slave_IO_Running: No
Slave_SQL_Running: Yes
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
- So,We need to get gtid_purged values from each separate source backups to ignore the deleted transactions in the binary log and troubleshoot above issues

cat mysqldump1.sql | grep GTID_PURGED | cut -f2 -d'=' | cut -f2 -d$'''
cat mysqldump2.sql | grep GTID_PURGED | cut -f2 -d'=' | cut -f2 -d$'''
- To set global GTID_PURGED values , needs to do reset master in percona galera cluster . If server is in cluster not possible to execute reset master command . Needs to disable wsrep_provider variable in wsrep.conf to execute reset master and restart mysql service in slave server
#wsrep_provider = /usr/lib/galera/libgalera_smm.so
- Once mysql service is restarted , we can able to do reset master in percona galera cluster server and set GTID_PURGED values
Set GTID_PURGED Value :

Check Show Slave Status G :

We able to see slave server is get synced in few minutes , and seconds_behind_master is 0
Check Show Processlist :
Highlighted the multi master servers ( two servers ) is syncing to slave server

Once completed all the steps , enable cluster wsrep_provider variable in wsrep.conf and restart mysql service in slave server
Verify once again the slave status and processlist :)
References :
External Replica Setup : https://cloud.google.com/sql/docs/mysql/replication/configure-external-replica
Get gtid_purged : https://dev.mysql.com/doc/refman/8.0/en/replication-multi-source-provision-slave.html
Set gtid_purged and troubleshoot : https://dev.mysql.com/doc/refman/8.0/en/replication-multi-source-provision-slave.html
Monday, November 25, 2019
MongoDB supports horizontal scaling of the data with the help of the shared key. Shared key selection should be good and poor shared key split the data in only a single shared
Today have tried a simple setup of MongoDB sharding with two shared nodes, sharing the simple steps to configure the same. Initially prepared with server lists and IP addresses of each server to avoid confusion by myself
Launched 6 ubuntu servers and installed mongo in all the servers, set hostname accordingly. As above 2 mongo shared, 1 mongo router and 3 mongo config servers have been launched. Before installing mongo update the system with the latest packages
sudo apt-get update && sudo apt-get upgrade

Then start installing the MongoDB in all the servers
1.sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E52529D4
2.sudo bash -c 'echo "deb http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/4.0 multiverse" > /etc/apt/sources.list.d/mongodb-org-4.0.list'
2.sudo bash -c 'echo "deb http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/4.0 multiverse" > /etc/apt/sources.list.d/mongodb-org-4.0.list'
3.sudo apt update
4.sudo apt install mongodb-org
5.systemctl enable mongod.service
6.systemctl start mongod.service
For secure authentication, MongoDB recommends the X.509 certificate to secure connections between production systems. we need to create a key file for secure authentication between the members of your replica set.
Initially in primary config server create the key file with OpenSSL and copy the same SSL file to another server in the same location
1.openssl rand -base64 756 > mongo-keyfile
2.sudo mkdir /data/mongo
3.sudo mv ~/mongo-keyfile /data/mongo
4.sudo chmod 400 /data/mongo/mongo-keyfile
5.sudo chown mongodb:mongodb /data/mongo/mongo-keyfile
Once a key file is created, add value in all the /etc/mongod.conf. Its should be same as below because mongod.conf file is case sensitive
security:
keyFile: /opt/mongo/mongodb-keyfile
sudo systemctl restart mongod
Main Components :
Config Server: This stores metadata and configuration settings for the rest of the cluster
Query Router: The Mongols daemon acts as an interface between the client application and the cluster shards. It’s like a listener of mongo instances
Shard: A database server that holds a portion of your data. Items in the database are divided among shards either by range or hashing
Steps involving in the configuration :
1.Configure the config servers
2.Configure the Query Router
3.Configure the sharding
1.Configure the config servers
Using single config server is not enough to maintain the metadata at the time of the disaster, we are setting up one primary and two secondary replica set
On each config server, edit below values in mongod.conf. bind IP values will be different for each server

Then restart mongo service using below command on each config servers
sudo systemctl restart mongod
Once restarted initiate the config server using below command, please replace the hostnames accordingly

And do check the rs.status of config server replica sets

Configuring the config server is completed, let's move on next steps
2.Configure the Query Router
Using the config server metadata information, send read and write queries to the correct shards
Create /etc/mongos.conf file and add the below lines

Create a new systemd unit file for mongos called /lib/systemd/system/mongos.service

Once we created files, needs to enable systemctl for mongos.service using below commands
1.sudo systemctl stop mongod
2.sudo systemctl enable mongos.service
3.sudo systemctl start mongos
4.systemctl status mongos
1.sudo systemctl stop mongod
2.sudo systemctl enable mongos.service
3.sudo systemctl start mongos
4.systemctl status mongos
3.Configure the sharding servers
On each shared server, edit below values in mongod.conf. Bind IP values will be different for each server and restart the mongod service

Once everything is completed, using mongo query router address login into any one of shared servers, I have created a separate admin user for MongoDB. If required create it
mongo 172.31.42.214:27017 -u adminuser -p --authenticationDatabase admin
Connect mongos interface and add the shared nodes, if you have replica set for shared nodes steps will be different to add shared

It’s done, shared000 and shared001 are added. There are many links available for sharding the database and collections to mangos. Tried with below examples for my test and its working as expected

Thanks for reading !!!
Tuesday, July 21, 2015
Before proceeding installation things , go through cluster basics from the MySQL website and forums. It will be helpful to easily understand installation and configuration. First time is difficult to get things to done in one shot is not possible , no problem will learn it .
MySQL Cluster Installation will be mostly done by two ways.,
- Using binaries
- rpm(Rethat,CentOS..,)
Different Linux flavors has different methods to install format , here I have explaining with CentOS7 .
1.Have prepared two different machines to install MySQL Cluster . First you have to login two different machines
2.Be ready with mysql rpm's

3.Now get ready to start installation of MySQL Cluster
Create mysql user ...

4.Install downloaded Server and Client rpm's in both VM

5.MySQL Server needs to be install fully

6.Please verify cluster/mysql folder,once installation is completed


All files needs to be there , for MySQL Cluster you will get new database called ndbinfo .
7.This is time to create configuration file for mysql cluster environment
Only two configuration files needs to create for mysql cluster
8.This is very important step you follow before you get into cluster environment
You have to start cluster as below.,


2. Start data node in both mysqlone and mysqltwo


3. Start SQL node in both mysqlone and mysqltwo , after data node is up . If you start before data node might be crash.
9.Now you have to check cluster status in any one of VM machine , using ndb_mgm utility

Once you start the data node , it will be in starting mode . Meanwhile you have to check howmuch data and index memory cluster is using as below.,

It will be start slowly never expect as much as you started , once data and management node start you will see like below.,

if data and index usage is above 90% you have to increase RAM memory and increase data memory , index memory parameter changes in config.ini file .
10.After you have to started Data node you will needs to start the SQL Node as said before

Once you started management,data and sql node in order wise . You ready with access high availability feature in MySQL .
Please contact me if you need further assistance on MySQL support , Thanks in advance .
1.Have prepared two different machines to install MySQL Cluster . First you have to login two different machines
 |
| Two VM Machines |

3.Now get ready to start installation of MySQL Cluster
Create mysql user ...

4.Install downloaded Server and Client rpm's in both VM

5.MySQL Server needs to be install fully

6.Please verify cluster/mysql folder,once installation is completed


All files needs to be there , for MySQL Cluster you will get new database called ndbinfo .
7.This is time to create configuration file for mysql cluster environment
Only two configuration files needs to create for mysql cluster
- my.cnf for mysql (SQL node)
- config.ini for cluster
[ndbd default]# Options affecting ndbd processes on all data nodes:NoOfReplicas=2 # Number of replicas#DataMemory=80M # How much memory to allocate for data storage#IndexMemory=18M # How much memory to allocate for index storage# For DataMemory and IndexMemory, we have used the# default values. Since the "world" database takes up# only about 500KB, this should be more than enough for# this example Cluster setup.#[tcp default]# TCP/IP options:# portnumber=2202 # This the default; however, you can use any# port that is free for all the hosts in the cluster# Note: It is recommended that you do not specify the port# number at all and simply allow the default value to be used# instead[ndb_mgmd]# Management process options:NodeID=1hostname=192.168.159.131 # Hostname or IP address of MGM node[ndb_mgmd]# Management process options:NodeID=2hostname=192.168.159.134 # Hostname or IP address of MGM node[ndbd]# Options for data node "A":# (one [ndbd] section per data node)NodeID=3hostname=192.168.159.131 # Hostname or IP addressdatadir=/var/lib/mysql-cluster/ # Directory for this data node's data files[ndbd]# Options for data node "B":NodeID=4hostname=192.168.159.134 # Hostname or IP addressdatadir=/var/lib/mysql-cluster/ # Directory for this data node's data files[mysqld]# SQL node options:NodeID=5
Same file you have to prepare and place in /var/lib/mysql-cluster directory . If any single word is missed cluster will not be start properly.
As per standalone mysql setup you have to prepare my.cnf file for SQL Node
You have to start cluster as below.,
- Start management node in both mysqlone and mysqltwo


2. Start data node in both mysqlone and mysqltwo


3. Start SQL node in both mysqlone and mysqltwo , after data node is up . If you start before data node might be crash.
9.Now you have to check cluster status in any one of VM machine , using ndb_mgm utility

Once you start the data node , it will be in starting mode . Meanwhile you have to check howmuch data and index memory cluster is using as below.,

It will be start slowly never expect as much as you started , once data and management node start you will see like below.,

if data and index usage is above 90% you have to increase RAM memory and increase data memory , index memory parameter changes in config.ini file .
10.After you have to started Data node you will needs to start the SQL Node as said before

Once you started management,data and sql node in order wise . You ready with access high availability feature in MySQL .
Please contact me if you need further assistance on MySQL support , Thanks in advance .